





































这才是DeepSeek的正确使用方式!(DeepSeek本地部署快速指南)
- 来源: 金舟软件
- 作者:Kylin
- 时间:2025-03-26 19:27:12




 官方正版
官方正版
 AI摘要
AI摘要
本文详细介绍了本地部署DeepSeek大语言模型的三大优势:数据安全(敏感数据不出本地)、性能稳定(不受网络波动影响)和成本效益。同时提供了两种5分钟快速部署方法:使用官方部署工具或手动安装Ollama+Chatbox,并附上硬件配置建议和常见问题解决方案。无论企业还是个人,都能轻松在本地搭建专属AI助手,安全高效地处理各类任务。
摘要由平台通过智能技术生成一、为何选择本地部署DeepSeek?
在AI技术飞速发展的当下,DeepSeek作为一款备受瞩目的大语言模型,以其卓越的性能和广泛的应用潜力,吸引了众多开发者和企业的目光。而选择本地部署DeepSeek,更是能解锁诸多独特优势,让我们从数据安全、性能表现和成本效益三个关键维度来一探究竟。
1.1数据安全有保障
在这个数据驱动的时代,数据安全无疑是重中之重。对于企业,尤其是医疗、金融等对数据隐私和合规要求极高的行业来说,敏感数据一旦泄露,后果不堪设想。
⭕数据安全:本地部署DeepSeek,就如同为数据打造了一座坚不可摧的堡垒,所有数据都存储在本地,无需经过云端传输,从根本上杜绝了数据在云端存储和传输过程中可能遭遇的泄露风险。
⭕实际应用:以医疗行业为例,患者的病历、诊断数据等都包含着大量敏感信息,这些数据关乎患者的隐私和权益。通过本地部署DeepSeek,医院可以在内部搭建安全的AI环境,利用DeepSeek强大的自然语言处理能力进行病历分析、疾病诊断辅助等工作,同时确保患者数据的绝对安全,完全符合医疗数据合规要求。
同样,金融机构在处理客户的交易记录、资产信息时,也能借助本地部署的DeepSeek,实现对数据的严格管控,避免因数据泄露引发的信任危机和经济损失。
1.2性能表现更出色
网络波动常常是使用云端服务时的一大困扰,而本地部署DeepSeek则能彻底摆脱这一烦恼。无论处于离线状态,还是网络信号不佳的环境,只要本地硬件配置满足要求,DeepSeek就能稳定运行,为用户持续提供可靠的服务。
⭕快速处理:在面对复杂任务时,本地部署的DeepSeek更是展现出强大的处理能力。在代码生成方面,开发人员在本地利用DeepSeek进行代码编写和调试时,无需担心因网络延迟导致的代码补全不及时或生成结果卡顿的问题,大大提高了开发效率,能够更流畅地将自己的编程思路转化为实际代码。
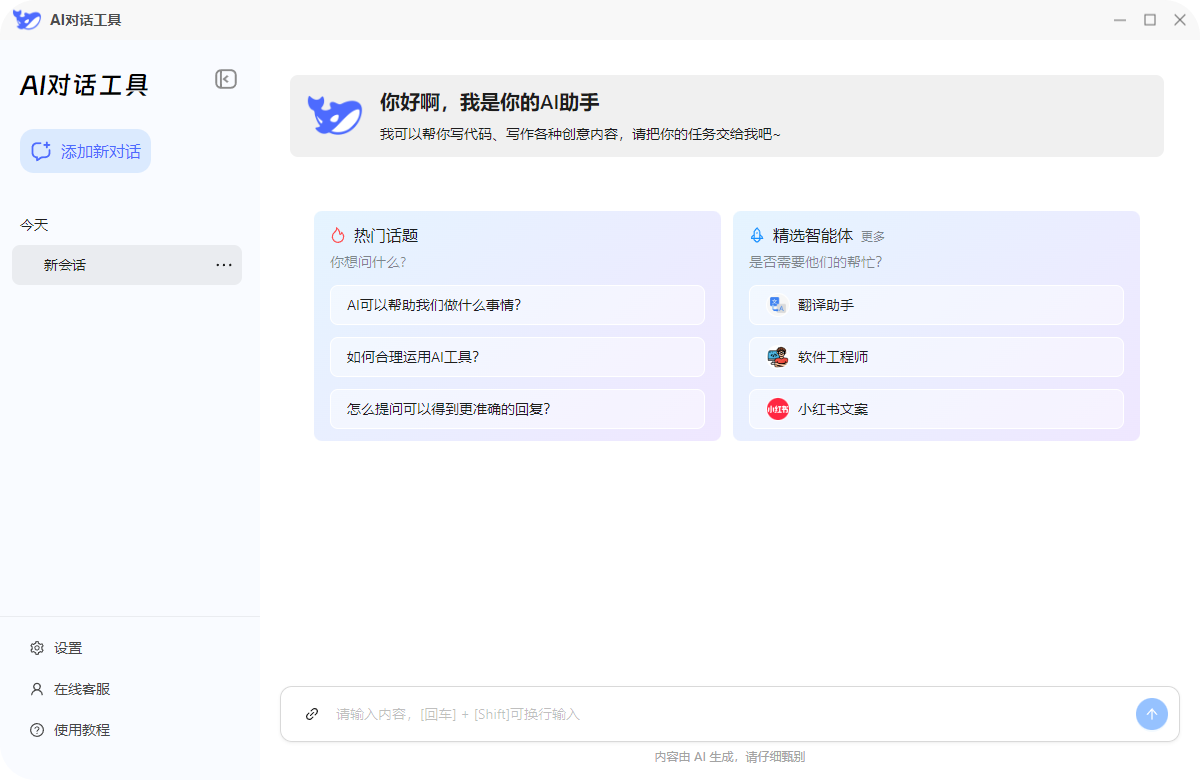
二、5分钟快速部署:保姆级教程
是不是已经迫不及待想要将DeepSeek部署到本地,开启高效AI之旅了?别着急,下面就为大家奉上一份超详细的5分钟快速部署教程,哪怕是技术小白也能轻松上手!
2.1准备工作
在开始部署之前,我们得先检查一下硬件和软件是否都准备就绪。
2.2安装DeepSeek本地部署工具
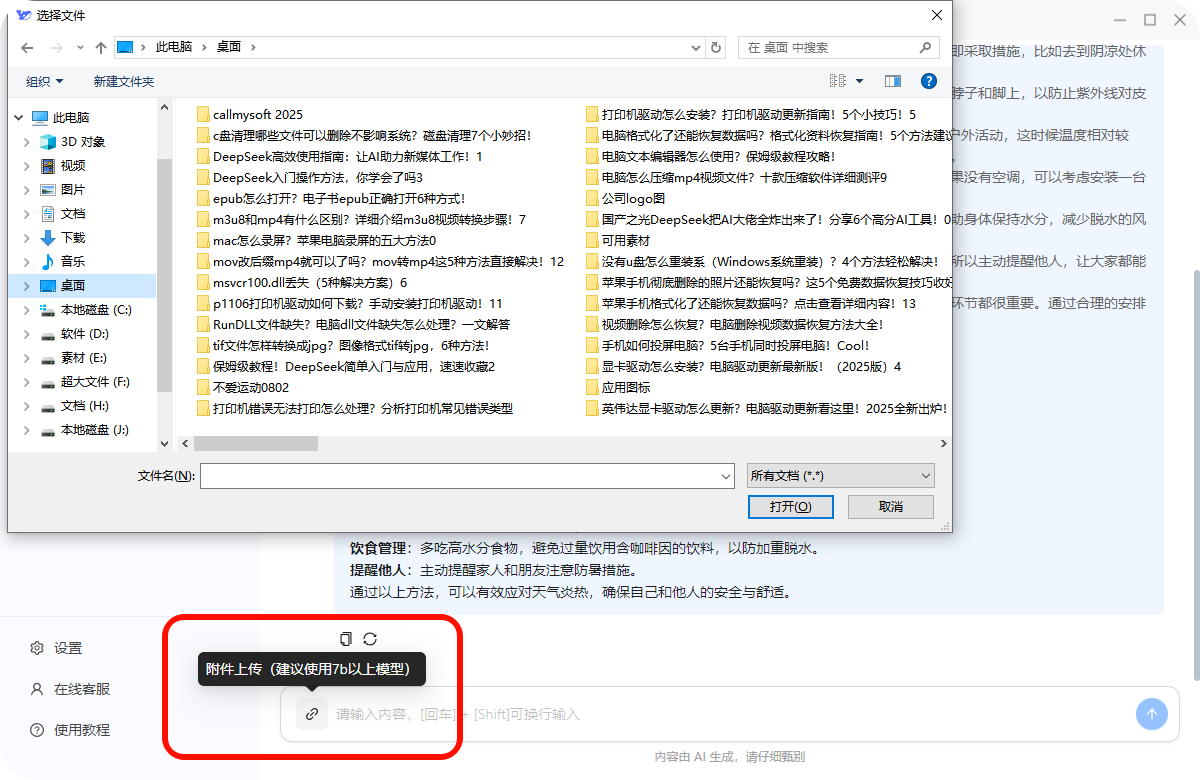
2.2.1访问“DeepSeek本地部署”的官网,下载软件的安装包。
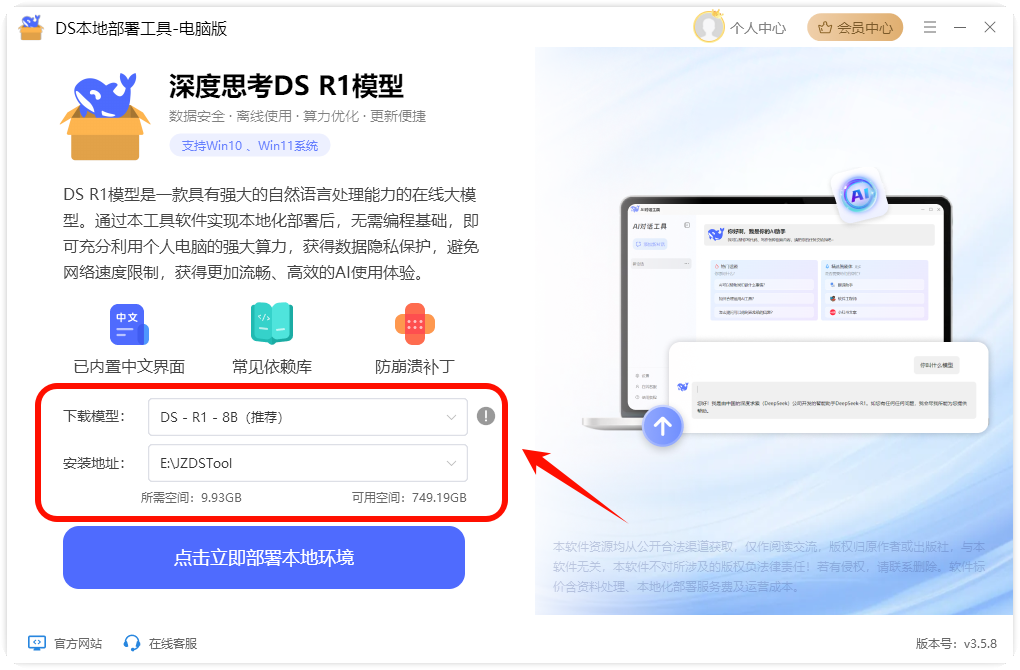
2.2.2双击安装包,允许并进入软件主页面,选择“下载模型”“安装地址”。
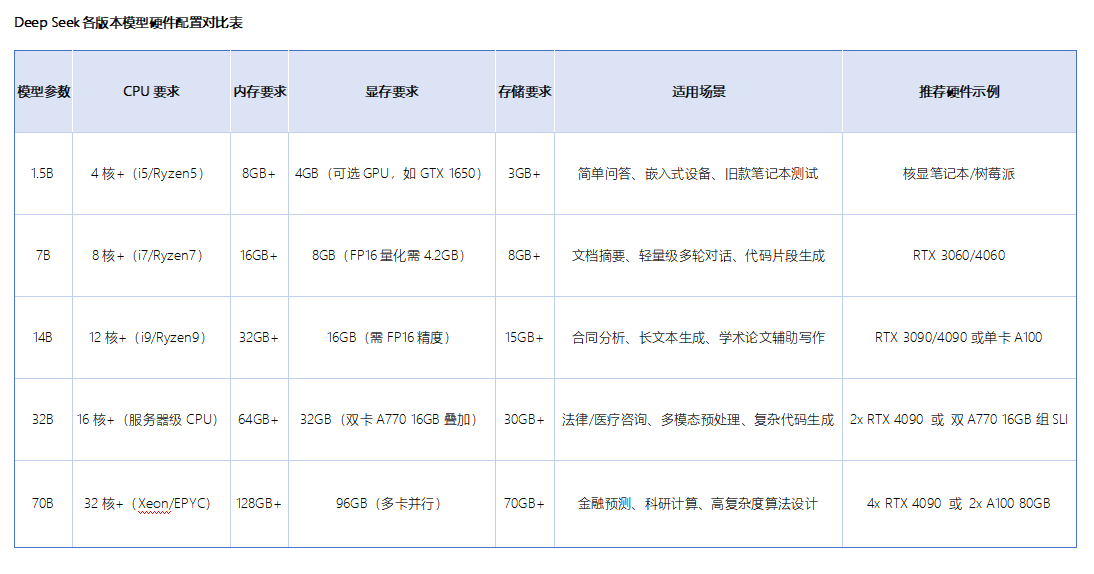
2.2.3根据电脑配置情况选择合适的模型,不同模型占用的内存大小不同。以下是小编整理出来的DeepSeek各版本模型硬件配置对比,大家可以结合自己的需求进行不同模型的选择下载。
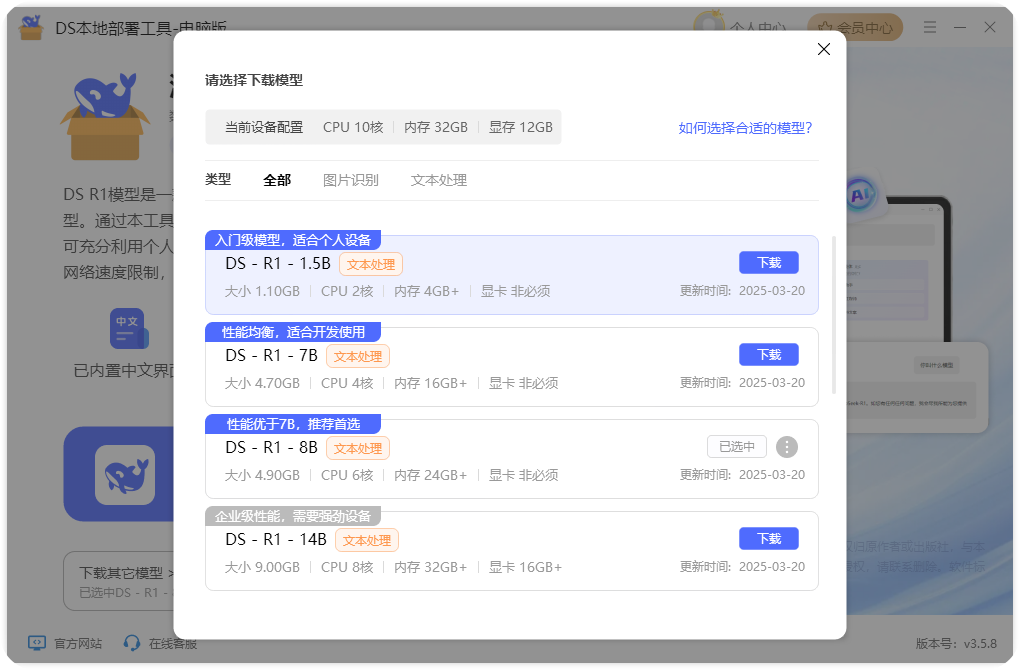
2.2.4部署完本地环境后,点击“立即启动”。弹出与AI的对话框,我们就可以选择不同的话题或智能体进行调校。
3.2手动部署DeepSeek安装环境
3.2.1电脑软硬件要求
⭕硬件:显卡建议选择RTX3060及以上型号,避免出现卡顿现象。内存要达到16GB+,有足够的空间来存储和处理数据,让模型的运行更加流畅。存储空间至少需要50GB+,用于存放DeepSeek模型文件以及相关的运行环境文件,为模型的稳定运行提供充足的“仓库”。
⭕软件:我们需要安装Ollama和Chatbox。Ollama是一个开源的本地化工具。Chatbox则是一款可视化交互工具。

3.2.2部署步骤
3.2.2.1安装Ollama。访问Ollama官网,根据自己的操作系统选择对应的安装包进行下载。接下来,我们通过Ollama来安装DeepSeek模型。Ollama会自动从模型库中下载并安装DeepSeek模型,这个过程可能需要一些时间,具体时长取决于你的网络速度和模型大小,请耐心等待。
3.2.2.2下载并安装Chatbox。同样,访问Chatbox官网,下载适用于你操作系统的安装包,然后按照常规的软件安装步骤进行安装即可。进入设置页面,在“API配置”选项中,选择“ollamaapi”。
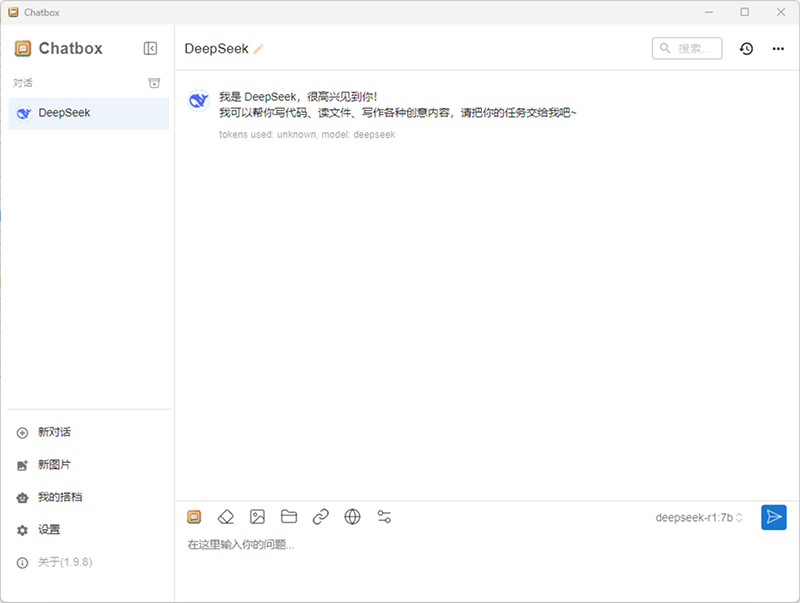
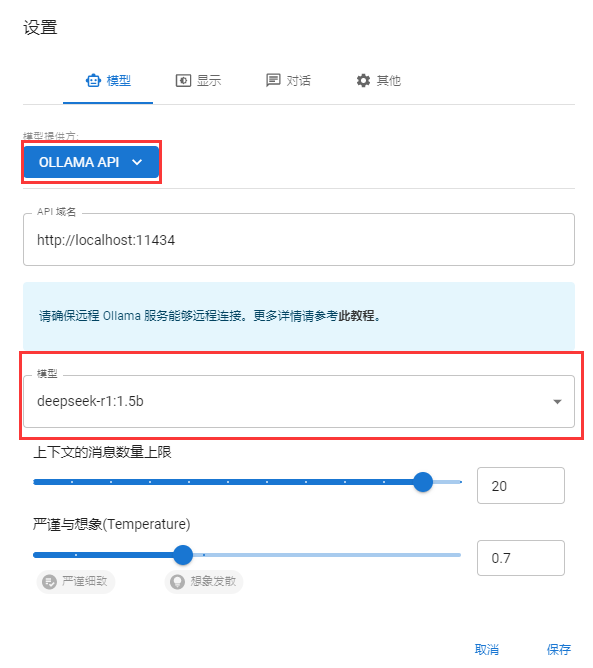
3.2.2.3选择已安装的DeepSeek模型。在Chatbox的模型选择下拉菜单中,你会看到之前通过Ollama安装的DeepSeek模型,选择对应的模型,点击保存。
现在,你可以在Chatbox中输入各种问题,与本地部署的DeepSeek模型进行畅快淋漓的对话了。无论是让它帮你写一篇文章、解答专业问题,还是进行创意头脑风暴,DeepSeek都能给你带来意想不到的惊喜!
三、常见问题解答
在部署和使用DeepSeek的过程中,大家可能会遇到一些问题,别担心,下面就为大家一一解答!
3.1模型加载失败
如果你在加载DeepSeek模型时遇到失败的情况,首先要确保模型文件的扩展名为.gguf。.gguf格式是专门为在本地运行大型语言模型设计的一种二进制格式,它能够有效地提高模型的加载速度和运行效率。
如果模型文件的扩展名不是.gguf,你可以检查一下下载的模型是否完整,或者尝试重新下载模型。另外,还要检查LMStudio是否为最新版本,旧版本可能存在兼容性问题,导致无法正常加载模型。
3.2运行速度慢/GPU未调用
当你发现DeepSeek运行速度慢,或者GPU未被调用时,首先要确认是否已安装最新的CUDA驱动。CUDA是NVIDIA推出的一种并行计算平台和编程模型,它能够让GPU发挥出强大的计算能力,加速DeepSeek的运行。
推荐阅读:




温馨提示:本文由金舟软件网站编辑出品转载请注明出处,违者必究(部分内容来源于网络,经作者整理后发布,如有侵权,请立刻联系我们处理)
 已复制链接~
已复制链接~





